Error-correcting codes
Note: all arithmetic to follow is done over
![]() .
.
Rectangular codes
Idea: a message is a bit string of length ![]() . Arrange the bits of
the message in a
. Arrange the bits of
the message in a ![]() rectangle, and add a parity check bit at
the end of each row and column. This results in a code word of length
rectangle, and add a parity check bit at
the end of each row and column. This results in a code word of length
![]() .
.
To decode: find the sum of each row and column of the encoded
rectangle. If exactly one row sum (of row ![]() ) and one column sum (of
column
) and one column sum (of
column ![]() ) equal 1, then an error occurred in the
) equal 1, then an error occurred in the ![]() -th row and the
-th row and the
![]() -th column. Change this bit to decode. If more than one row sum or
more than one column sum equal 1, then the information is ambiguous
and decoding is not possible.
-th column. Change this bit to decode. If more than one row sum or
more than one column sum equal 1, then the information is ambiguous
and decoding is not possible.
Example: take ![]() ,
, ![]() . So the messages are all bit strings of
length 6. Take for example the message
. So the messages are all bit strings of
length 6. Take for example the message ![]() .
.
Arrange in rectangle and add parity bits:
| 1 | 1 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
So the codeword has length ![]() . Moreover, each codeword, when
arranged in a
. Moreover, each codeword, when
arranged in a ![]() rectangle, has all row and column sums equal
to zero.
rectangle, has all row and column sums equal
to zero.
Decoding: suppose the word ![]() is received. Arrange in
rectangle:
is received. Arrange in
rectangle:
| 1 | 1 | 1 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
The row sums are 1,0,0, respectively, and the column sums are
0,0,1,0, respectively. So only row 1 and column 3 have sum equal to 1,
so we can assume that an error occurred in the first row, third
column. If we correct this bit, we
obtain the code word given above.
Definition: a code is linear if the following holds: if ![]() and
and ![]() are codewords, then
are codewords, then ![]() is also a code word.
is also a code word.
A rectangle code is a linear code.
Syndromes
Consider the rectangle code given before. In the example given above,
we obtained row sums 1,0,0, and column sums 0,0,1,0. The word
consisting of the row sums and column sums is called the syndrome of the received word. So for our example, the syndrome
equals 1000010.
The syndrome can also be calculated directly from the received word
![]() , without using the rectangle. For the first bit of
the syndrome (the sum of the first row), we add bits 1, 2, 3 and 4 of
the received word. For the second, we add bits 5, 6, 7, and 8. For the
third, we add bits 9, 10, 11, 12. For the fourth syndrome bit, which
gives the sum of the first column, we add bits 1, 5 and 9. For the
fifth syndrome bit, we add bits 2, 6, and 10, etc.
, without using the rectangle. For the first bit of
the syndrome (the sum of the first row), we add bits 1, 2, 3 and 4 of
the received word. For the second, we add bits 5, 6, 7, and 8. For the
third, we add bits 9, 10, 11, 12. For the fourth syndrome bit, which
gives the sum of the first column, we add bits 1, 5 and 9. For the
fifth syndrome bit, we add bits 2, 6, and 10, etc.
In general, if we receive the word
![]() , then the
syndrome bits
, then the
syndrome bits
![]() are given by:
are given by:
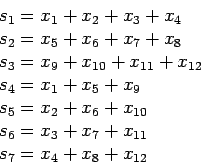
This can be written in matrix form:
![\begin{displaymath}
\left[\begin{array}{cccccccccccc}
1&1&1&1&0&0&0&0&0&0&0&0\\ ...
...{c}
s_1\\ s_2\\ s_3\\ s_4\\ s_5\\ s_6\\ s_7
\end{array}\right]
\end{displaymath}](img19.gif)
The matrix representing the parity checks is called the parity
check matrix, and is usually called ![]() .
.
Every code word has syndrome equal to the zero vector, and in fact,
any word ![]() for which
for which ![]() is a code word. Therefore,
is a code word. Therefore, ![]() completely defines the code.
completely defines the code.
The next question: can we define other
matrices ![]() that may give a better code?
that may give a better code?
Hamming codes
Hamming codes are codes that can correct one error. They are defined
by their parity check matrix, which is a socalled Hamming matrix. The
parity check matrix will be decoded by ![]() .
.
First we take a closer look at the parity check matrix and its properties. An
error that occurred in a code word ![]() can be represented by an error
vector
can be represented by an error
vector ![]() , in the sense that the received word
, in the sense that the received word ![]() is the sum of the
code word and the error vector:
is the sum of the
code word and the error vector: ![]() . In the example given before,
. In the example given before,
![]() ,
,
![]() , and
, and
![]() .
.
Now the syndrome ![]() can be computed, as explained, by a matrix
computation:
can be computed, as explained, by a matrix
computation: ![]() . But
. But
![]() . Since
. Since ![]() is a code word,
is a code word,
![]() , so we get that
, so we get that ![]() . We can compute the syndrome, but how
can we determine the error vector from the syndrome?
. We can compute the syndrome, but how
can we determine the error vector from the syndrome?
In the case on one-error-correcting codes this is easy. In this case,
![]() can always be assumed to be a vector of Hamming weight at most 1
(in other words, with at most one 1). Suppose
can always be assumed to be a vector of Hamming weight at most 1
(in other words, with at most one 1). Suppose ![]() has a 1 in the
has a 1 in the
![]() -th position. Then
-th position. Then ![]() will be exactly equal to the
will be exactly equal to the ![]() -th column
of
-th column
of ![]() (easy to check). So if we know the syndrome, which is equal to
(easy to check). So if we know the syndrome, which is equal to
![]() , it is easy to determine
, it is easy to determine ![]() : just find out which column of
: just find out which column of ![]() is equal to the syndrome.
is equal to the syndrome.
In the example of the rectangle code, some syndromes do not correspond
to any column of ![]() . Take, for example,
. Take, for example,
![]() . The
syndrome is (check this!)
. The
syndrome is (check this!) ![]() , which does not correspond to
any column of
, which does not correspond to
any column of ![]() . So there is no code word at Hamming distance 1 from
. So there is no code word at Hamming distance 1 from
![]() , and we cannot decode
, and we cannot decode ![]() .
.
The idea for the Hamming code is to let this situation never
happen. Therefore, the parity check matrix for a Hamming code with
parameter ![]() will have as its columns all possible bit strings
of length
will have as its columns all possible bit strings
of length ![]() , except for
, except for ![]() . So
. So ![]() has
has ![]() columns
and
columns
and ![]() rows, and code words have
rows, and code words have ![]() bits, while syndromes have
bits, while syndromes have
![]() bits. For example, the Hamming matrix for
bits. For example, the Hamming matrix for ![]() is:
is:
![\begin{displaymath}
H=\left[\begin{array}{ccccccc}
1&0&1&0&1&0&1\\
0&1&1&0&0&1&1\\
0&0&0&1&1&1&1
\end{array}\right]
\end{displaymath}](img40.gif)
For example, take ![]() , then
, then ![]() , so
, so ![]() is a
codeword. Take
is a
codeword. Take ![]() . Then
. Then ![]() , which is equal to the
third column. So we know that the error occurred in the third bit. If
, which is equal to the
third column. So we know that the error occurred in the third bit. If
![]() , then
, then ![]() , so the word would get decoded as
, so the word would get decoded as
![]() . Indeed, we see that
. Indeed, we see that
![]() and
and
![]() both give the same answer
both give the same answer ![]() . However, since it is more likely
that one error occurs than two, the decoding makes sense.
. However, since it is more likely
that one error occurs than two, the decoding makes sense.
The Hamming code consists of all code words so that ![]() . This means
that, in linear algebra terms, the code is the null space of the
matrix
. This means
that, in linear algebra terms, the code is the null space of the
matrix ![]() . It also follows from a theorem in linear algebra that the
dimension of the null space equals the number of columns of
. It also follows from a theorem in linear algebra that the
dimension of the null space equals the number of columns of ![]() (7 in our example,
(7 in our example, ![]() in general) minus the rank of
in general) minus the rank of ![]() (3 in our example,
(3 in our example, ![]() in general). So a Hamming code with parameter
in general). So a Hamming code with parameter
![]() is a vector space of dimension
is a vector space of dimension ![]() , where
, where ![]() . This means
that the code has a basis of
. This means
that the code has a basis of ![]() vectors, and any code
word can be represented as a linear combination of the basis
vector. Since we are working in
vectors, and any code
word can be represented as a linear combination of the basis
vector. Since we are working in
![]() , the coefficients can only
take values 0 and 1. So to form a linear combination of the basis
vectors, we have exactly two choices for each basis vector: either
include it (coefficient equals 1) or not (coefficient equals 0). So in
total, there are
, the coefficients can only
take values 0 and 1. So to form a linear combination of the basis
vectors, we have exactly two choices for each basis vector: either
include it (coefficient equals 1) or not (coefficient equals 0). So in
total, there are ![]() possible linear combinations of the
possible linear combinations of the ![]() basis vectors, so there are
basis vectors, so there are ![]() code words.
code words.
Consider the set of words formed by a code word, and all code words at
Hamming distance 1 from it, in other words, all words that can be
obtained from the code word by making exactly one error. In our
example, one such set consists of the code word 0000000, and the words
1000000, 0100000, 0010000, 0001000, 0000100, 0000010, 0000001. Now in
order to be able to correct one error, the set of one code word must
be disjoint from the set of any other code word. Each such set has
size ![]() , where
, where ![]() is the length of the code word. Since all sets
are disjoint, the union of all these sets has exactly
is the length of the code word. Since all sets
are disjoint, the union of all these sets has exactly ![]() elements. Since there are only
elements. Since there are only ![]() possible words of length
possible words of length ![]() , we
have that
, we
have that
![]() , where
, where ![]() is the number of code words.
is the number of code words.
For Hamming codes, we just saw that ![]() , while
, while ![]() . So
we have that
. So
we have that
![]() . So we have
equality; this means that the sets just described exactly fill the
whole space of words of length
. So we have
equality; this means that the sets just described exactly fill the
whole space of words of length ![]() . In other words, every bit string
of length
. In other words, every bit string
of length ![]() is either a code word, or lies at Hamming distance 1
from a code word. So in this sense, Hamming codes are optimal;
it is not possible to make a bigger code (and thus be able to send
more different messages), if you are constrained to send words of
length
is either a code word, or lies at Hamming distance 1
from a code word. So in this sense, Hamming codes are optimal;
it is not possible to make a bigger code (and thus be able to send
more different messages), if you are constrained to send words of
length ![]() , and you want to be able to correct one error.
, and you want to be able to correct one error.
The representation of the code as a vector space also gives us the
way to encode a message. There are ![]() code words, so all bit
strings of length
code words, so all bit
strings of length ![]() can each receive their own code word. But,
given a bit string
can each receive their own code word. But,
given a bit string
![]() , how do we find the
corresponding code word? For this we use the basis vectors. As argued
before, the code has a basis of size
, how do we find the
corresponding code word? For this we use the basis vectors. As argued
before, the code has a basis of size ![]() , say consisting of vectors
, say consisting of vectors
![]() (note that each of these vectors has length
(note that each of these vectors has length
![]() ). Then we can map the message
). Then we can map the message ![]() to the code word
to the code word
![]() . This still means we have to
find a basis; this can be done with the standard methods of linear
algebra, but we will omit the details here.
. This still means we have to
find a basis; this can be done with the standard methods of linear
algebra, but we will omit the details here.